
Что такое «изображения на основе данных» (Data Driven Images)? В этой статье под таким определением я буду подразумевать изображения, в которых каждый пиксель содержит некоторую часть данных или связан как-то с данными.
Давайте посмотрим на анимацию внизу. Это визуализация романа Льва Толстого «Война и мир», который всем хорошо известен. В этой визуализации каждая точка содержит информацию об одном слове романа, а цвета символизируют номера томов романа. Всего в романе около 460 000 слов, и 460 тысяч соответствующих точек складываются в портрет Льва Толстого и другие диаграммы.

Note: Эта визуализация «тяжелая», посколькy содержит почти пол-миллиона точек, для отрисовки которых серверам Tableau Public нужно некоторое время.
Визуализация выше требовательна к ресурсам ПК, поэтому дальше мы рассмотрим другой виз, и на его примере построим Data Driven Pictures.
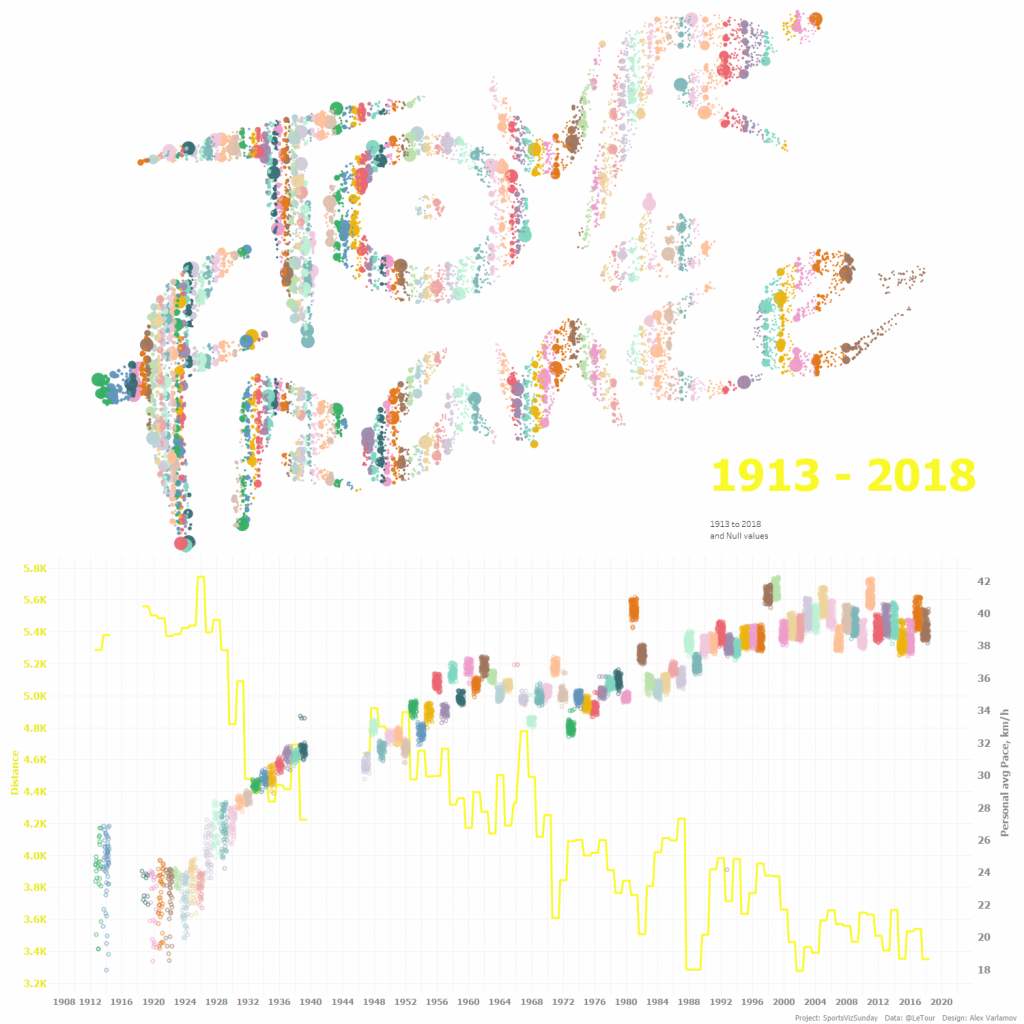
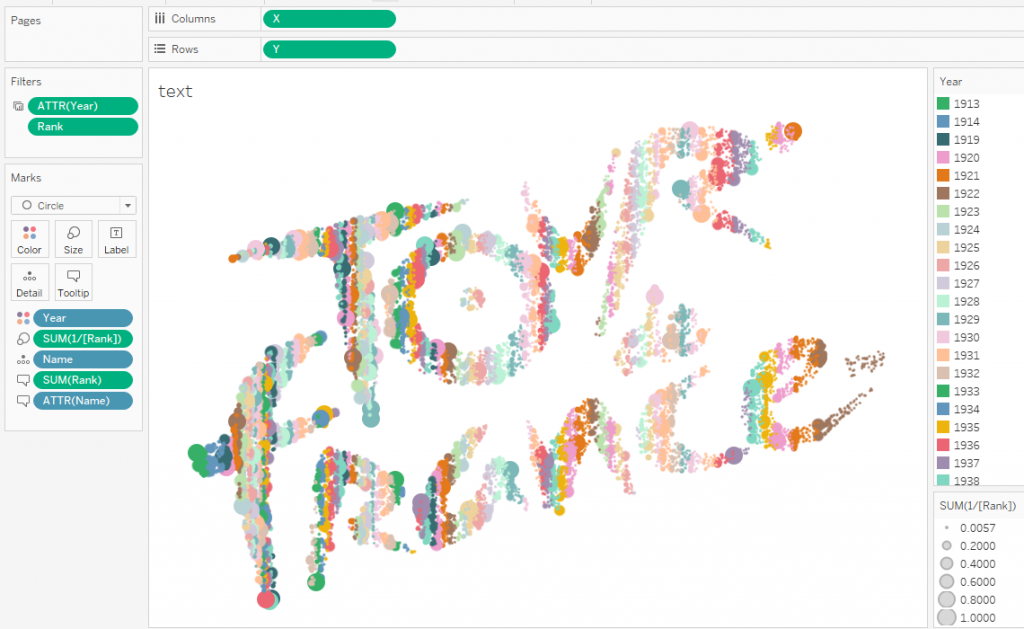
Этот проект был выполнен для #SportsVizSunday (см. виз внизу) в июле 2019г. и посвящен гонке Тур де Франс. Набор данных для этой визуализации содержит информациию о всех гонках за всю историю существования Тур де Франс c 1913 по 2018г. В визуализации я сделал лого Тур де Франс, составленное из кругов, где каждый круг — это один онщик в одном сезоне, цвета кругов определяют сезон, а размеры кругов — место конкретного гонщика в сезоне. Чем больше круг, тем быстрее пришел гонщик к финишу, соответственно, самые большие круги — это первые места в гонках. Иными словами, в каждом круге записана информация о гонщике и его месте в сезоне, а всё лого содержит данные за всю историю Тур де Франс.
1. Как сделать точечные изображения в Python
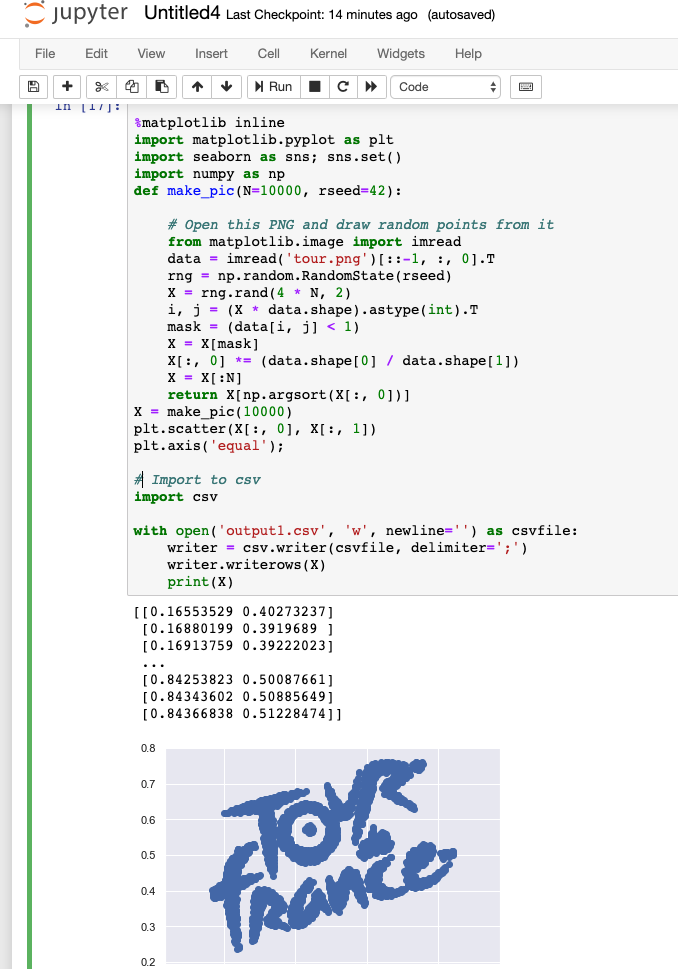
В этом разделе я покажу как сделать любое изображение или текст, сочтоящие из заданного количества точек. Ссылку на код я нашел в Твиттере пользователя @noookooon. Этот код написал Jake Vanderplas . Код позволяет превращать текст в точечные изображения с заданным количеством точек.
Оригинальный код не может экспортировать данные в файл и работает только с текстом. По умолчанию этот код использует картинку ‘Hello.png’, создаваемой этим же кодом.
Я добавил возможность экспорта в файл CSV, убрал цвета и добавил возможность работы с любой картинкой (PNG файлом).
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
def make_pic(N=1000, rseed=42):
# Open this PNG and draw random points from it
from matplotlib.image import imread
data = imread('che.png')[::-1, :, 0].T
rng = np.random.RandomState(rseed)
X = rng.rand(4 * N, 2)
i, j = (X * data.shape).astype(int).T
mask = (data[i, j] < 1)
X = X[mask]
X[:, 0] *= (data.shape[0] / data.shape[1])
X = X[:N]
return X[np.argsort(X[:, 0])]
X = make_pic(1000)
plt.scatter(X[:, 0], X[:, 1])
plt.axis('equal');
# Export to csv
export csv
with open('output1.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile, delimiter=';')
writer.writerows(X)
print(X)Для выполнения этого кода вам нужен Python 3 с библиотеками matplotlib, numpy and seaborn. Для работы с конкретным изображением нужно загрузить его в директорию питона на вашем компьютере.
Количество точек на конечной картинке определяется числом по умолчанию (1000) в строках:
def make_pic(N=1000, rseed=42):
X = make_pic(1000)Вы можете заменить это другим числом. Запустив этот код, получим координаты X и Y для каждой точки, они будут экспортированы в CSV файл. Лучше сразу подключить Tableau к этому CVS файлу и положить значения X и Y на полки Column and Row. Так вы можете видеть результат. Конечно, в питоне тоже можно видеть конечную картинку, но не очень удобно для этого использовать Jupyter Notebook или PyCharm, особенно с большим количеством точек.
Попробуем преобразовать PNG в точки. Возьмем официальный логотип Тур де Франс.
Ниже показано как работает код в Jupyter Notebook c этой картинкой, также мы получаем данные с координатами точек в CSV файле:
Когда вы работаете с неконтрастными цветными изображениями, результат может получиться неоднозначный. В таких случаях можно настроить порог контраста (contrast threshold), уменьшая '1' в строке:
mask = (data[i, j] < 1)Ниже приведен другой пример процессинга изображений. Это известный портрет Че Гевары, состоящий из одного миллиона точек.

Точечные портреты в Jupyter Notebook и Tableau:
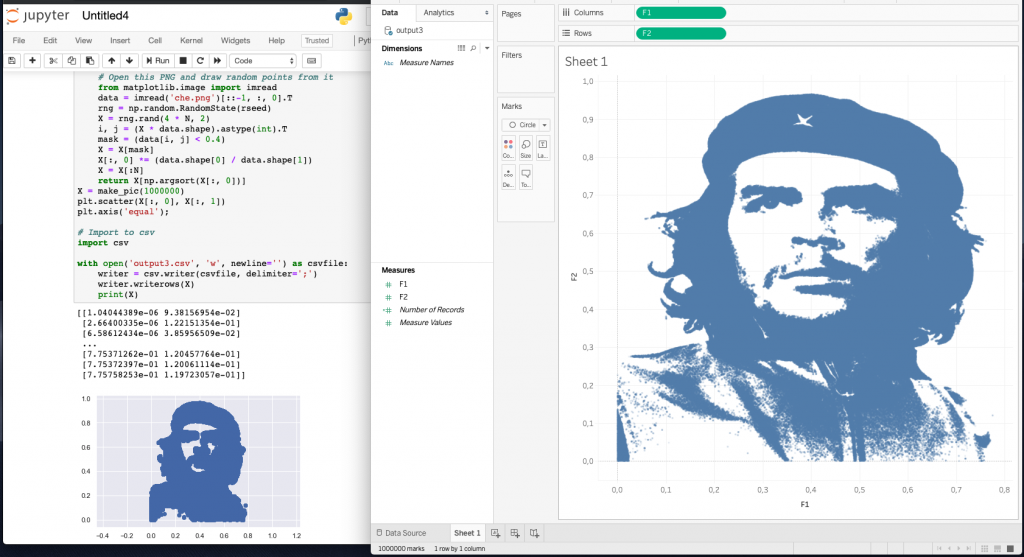
И финальная визуализация:

2. Объединение координат с данными
Мы научились создавать точечные портреты с заданным числом точек, сейчас нам нужно объединить эти точки с данными. Посмотрите количество строк в данных (или Number of Records в Tableau). Если число точек равно числу строк, то можно объединить (сджойнить) данныe по первичным ключам. Для этого можете просто пронумеровать строки в CSV файле с координатами и файле с данными, добавив столбцы ID в MS EXCEL (самый простой вариант). Соединяя эти датасеты через JOIN в Tableau, получим строгое соответствие одной строке данных одной паре координат (X;Y).
Теперь у нас есть объединенный датасет, с которым будем работать.
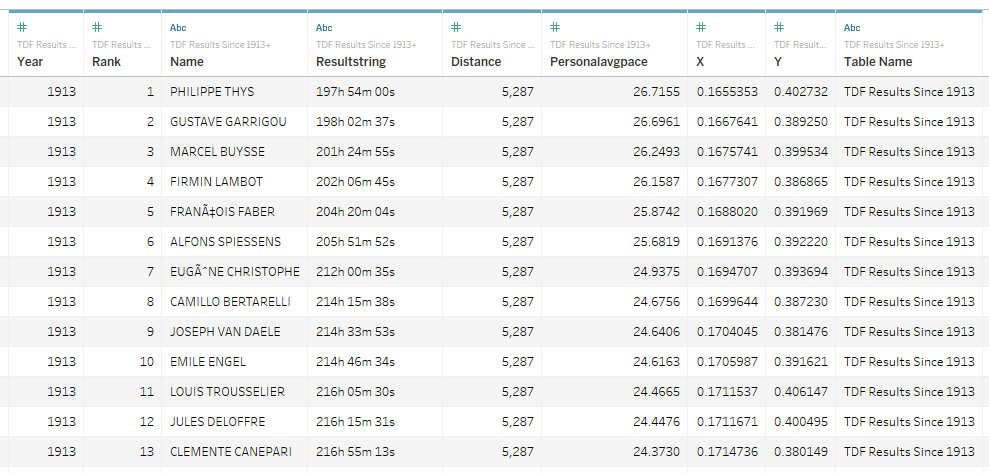
Итак, у нас есть датасет, в котором каждая точка с координатами X и Y имеет свой смысл. В нашем случае каждая точка символизирует одного гонщика в сезоне. Можно кодировать данные размерами, формами и цветами меток на визуализации. На визуализации ниже цвет обозначает сезон/год, а размер кругов - место гонщика в гонке каждого сезона.
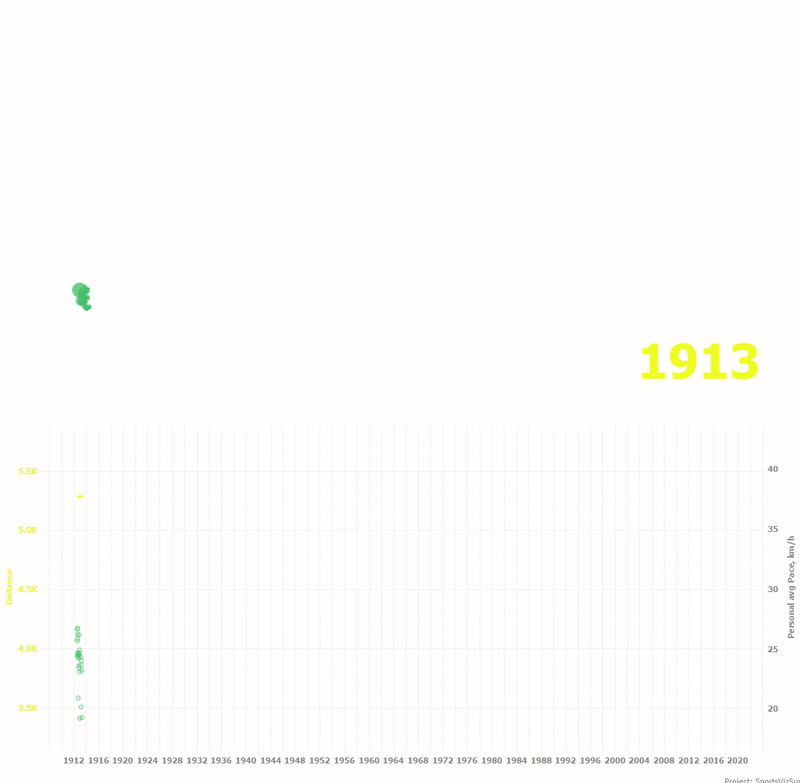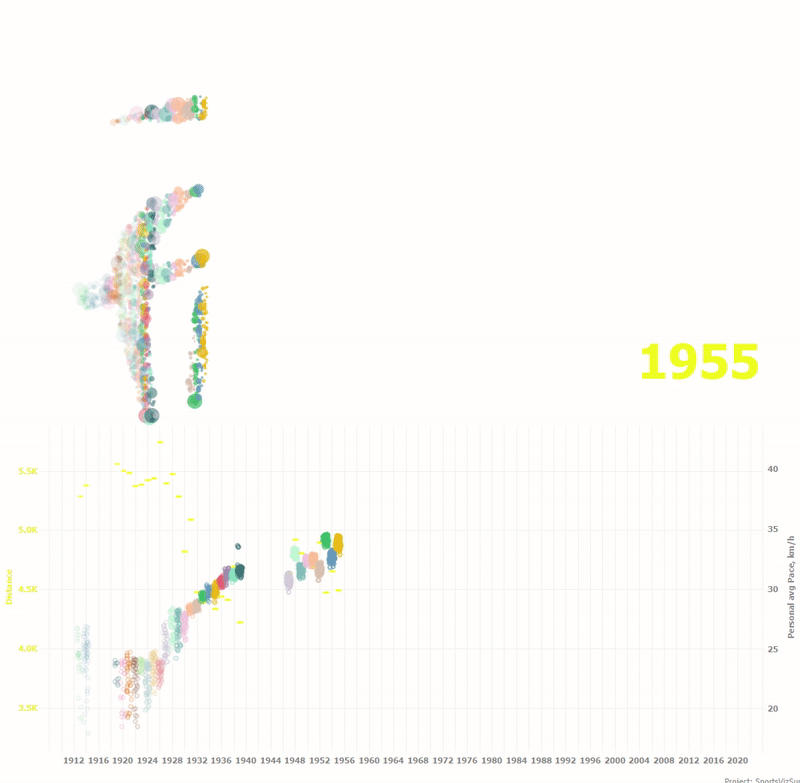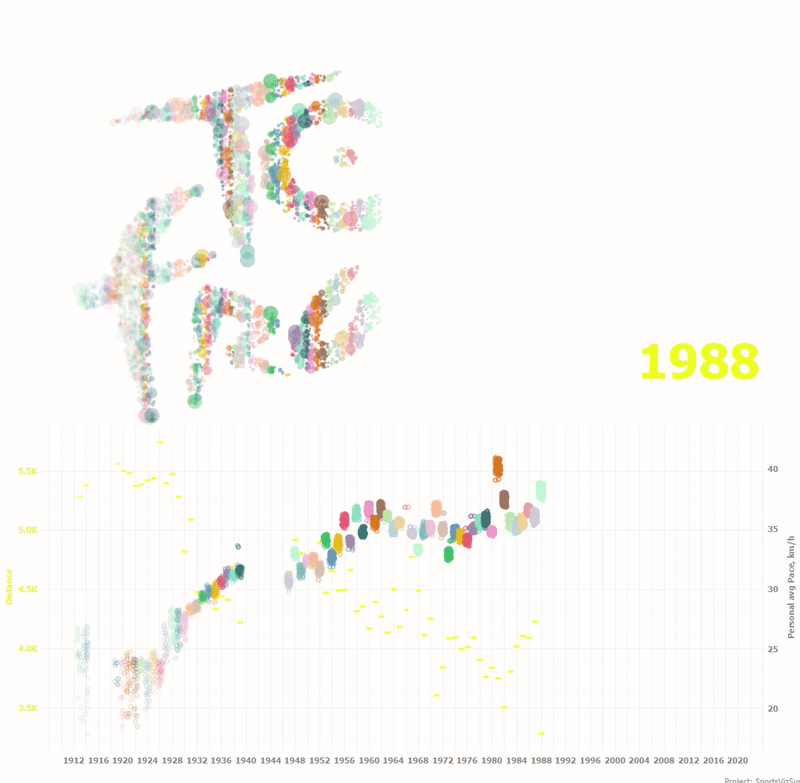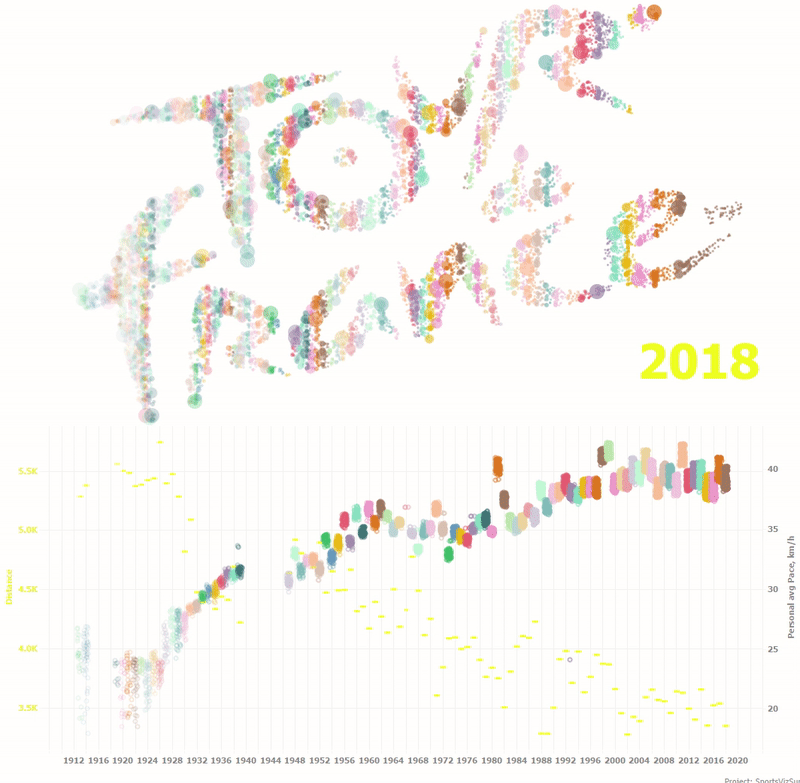
Внизу анимация показывает как изменялась дистанция годки и средние скорости по каждому гонщику на протяжении ста лет.
Я пользовался такой же техникой в визуализации "Война и Мир", которую упоминал выше. Сравните оригинальный и точечный портреты.

Заключение
Описанная в статье техника позволяет "записывать" данные в изображения. Возможно это звучит странно и непонятно, но мне нравится идея того, что каждая точка изображения имеет свой смысл или роль, являясь дата-атомом, и мы можем управлять перемещением таких точек, создавая интересные визуализации.