
В первой части статей о линейной регрессии «Линейная регрессия в Tableau, часть 1. Временные ряды» я рассматривал временные тренды. Однако наиболее часто регрессию используют для изучения связи между двумя однородными величинами, например, затратами и прибылью. Обе величины в этом случае имеют одинаковые единицы измерения (рубли или доллары например). Понятно что затраты первичны, а прибыль вторична, то есть, зависит от затрат. В этой статье я расскажу про нахождение трендов групп на примере данных кинематографа. Мы все знает о бюджетах фильмов и кассовых сборах, которые собирают фильмы — об этом часто пишут СМИ. Кроме этого есть различные рейтинговые системы, например, IMDB или TMDB, в которых рейтинги фильма определяются по десятибалльной шкале и строятся на основании голосования зрителей. Рейтинг TMDB достаточно авторитетный показатель, и на его основании зритель может выбирать фильмы чтобы не тратить время на плохое кино. А теперь давайте зададим себе вопросы:
- Будет ли при увеличении бюджета фильма расти линейно его прибыль?
- Есть ли разница в корреляции прибыли с бюджетом фильмов разных жанров (боевики, фэнтези и т.д.)?
- Будет ли тренд восходящим линейным при сравнении рейтинга TMDB с кассовыми сборами?
Мы задали себе несколько интересных вопросов или, говоря языком статистики, построили нулевые гипотезы. Теперь мы должны их либо подтвердить либо опровергнуть. Я нашел The Movies Dataset на kaggle.com. Эти данные содержат информацию о 45,000 фильмах до конца 2017 года на разных языках, 26 миллионов оценок фильмов от 270,000 зрителей на ресурсе MovieLens. Кроме того, в данных есть средние оценки фильмов на TMDB, кассовые сборы, бюджеты фильмов и другие метрики.
В этой статье я расскажу как создать инструмент поиска взаимосвязей между метриками и разбивать данные на группу. Конечная визуализация, которую будем делать, выглядит так:
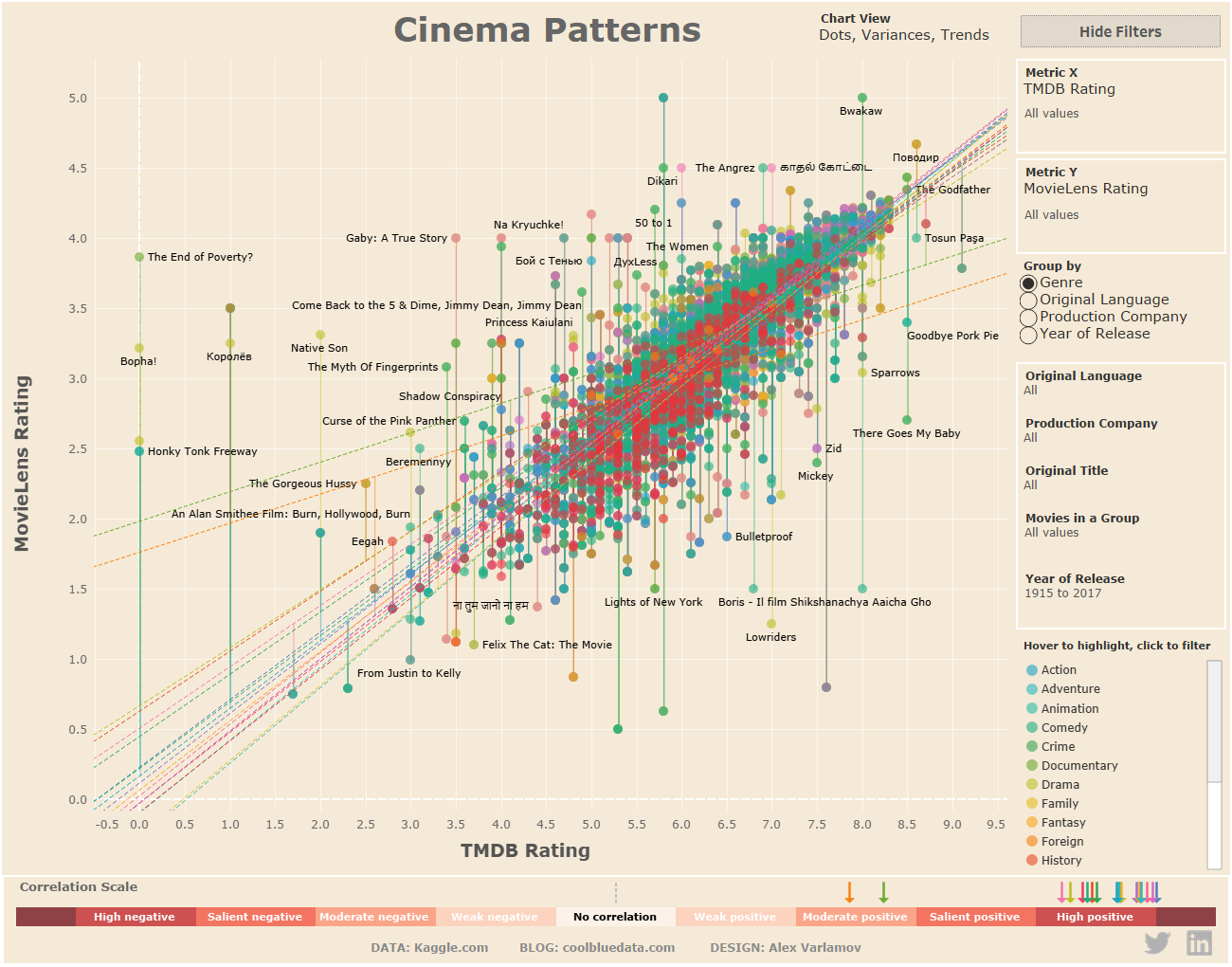
На скриншоте показана диаграмма разброса, характеризующая две системы оценки фильмов: TMDB (десятибалльная шкала) и MovieLens (пятибалльная шкала). Степень корреляции между двумя рейтинговыми метриками высокая в большинстве групп, то есть, зрители примерно одинаково голосуют за большинство фильмов. Но есть фильмы, которые сильно отклоняются от трендов.
1. Строим диаграмму разброса по группам
Корреляция между двумя величинами почти всегда визуализируется при помощи диаграммы разброса (scatter plot). Для ее построения в Tableau нужно подключить файлы данных. Архив данных содержит несколько файлов, нам нужны только файлы movies_metadata.csv, ratings.csv (в этом файле хранятся отзывы и оценки с ресурса MovieLens) и файл links.csv для соединения первых двух файлов:
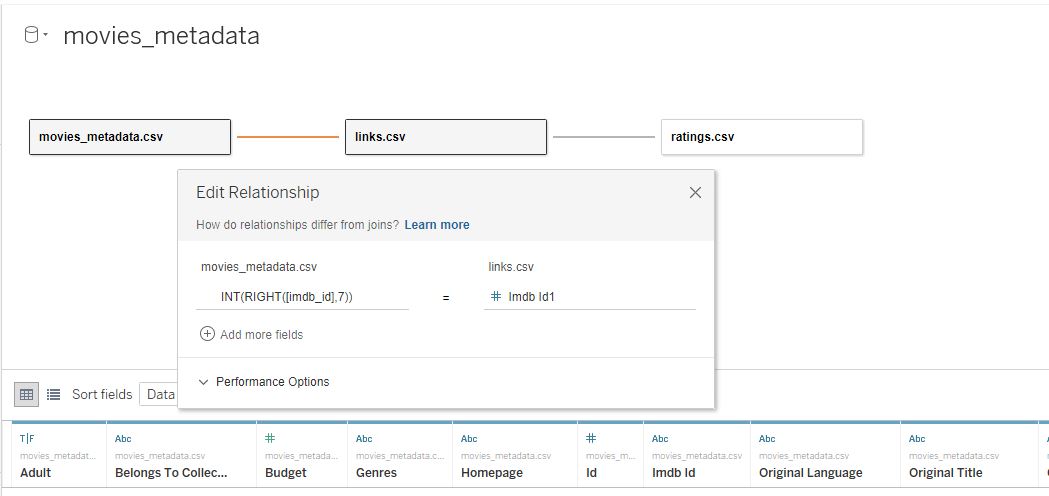
Важно: файл ratings.csv содержит более 20млн строк с каждым отзывом — это много, поэтому я уменьшил его объем до 5000 строк, агрегируя оценки и количество голосовавших. Это сделал в Tableau Prep.
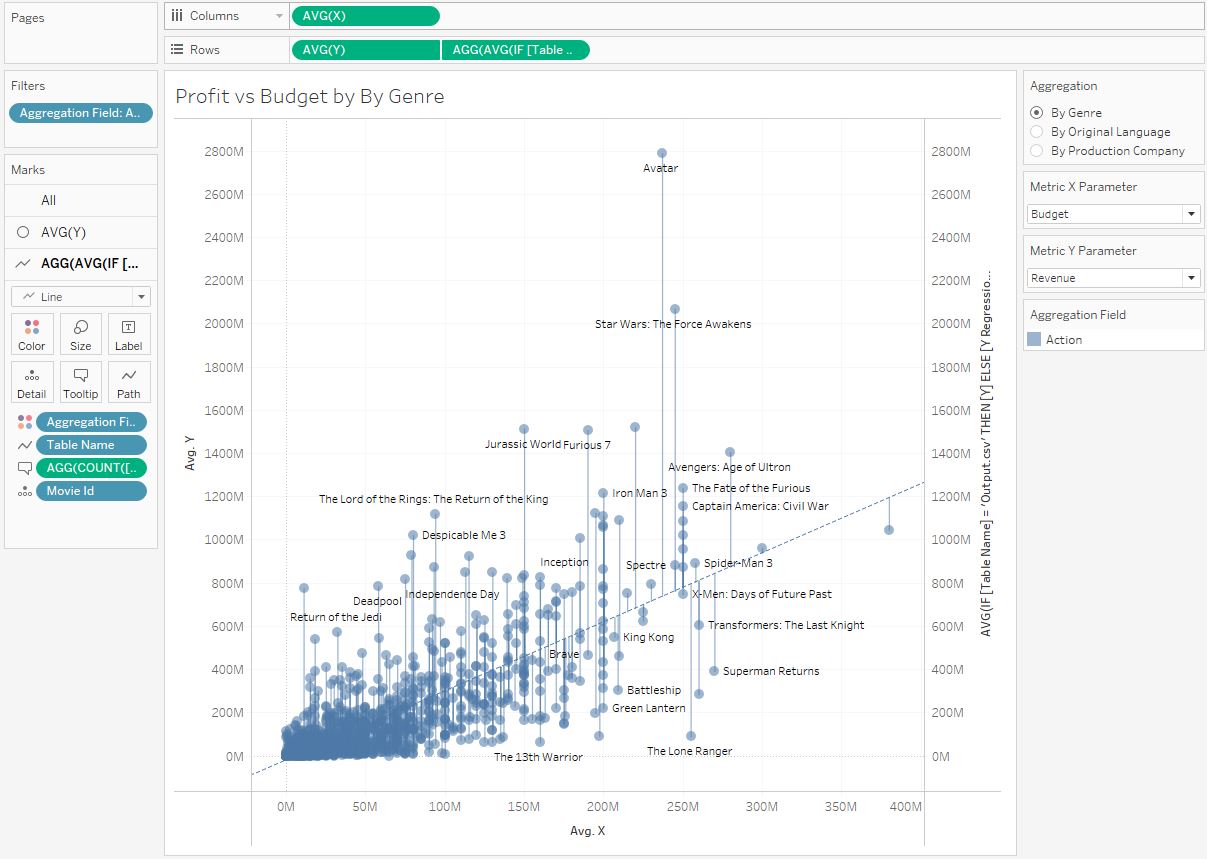
В данных есть поля Budget (бюджет) и Revenue (выручка). Сделаем поле Profit (прибыль): [Revenue] — [Budget] Теперь построим диаграмму разброса Profit vs Budget:
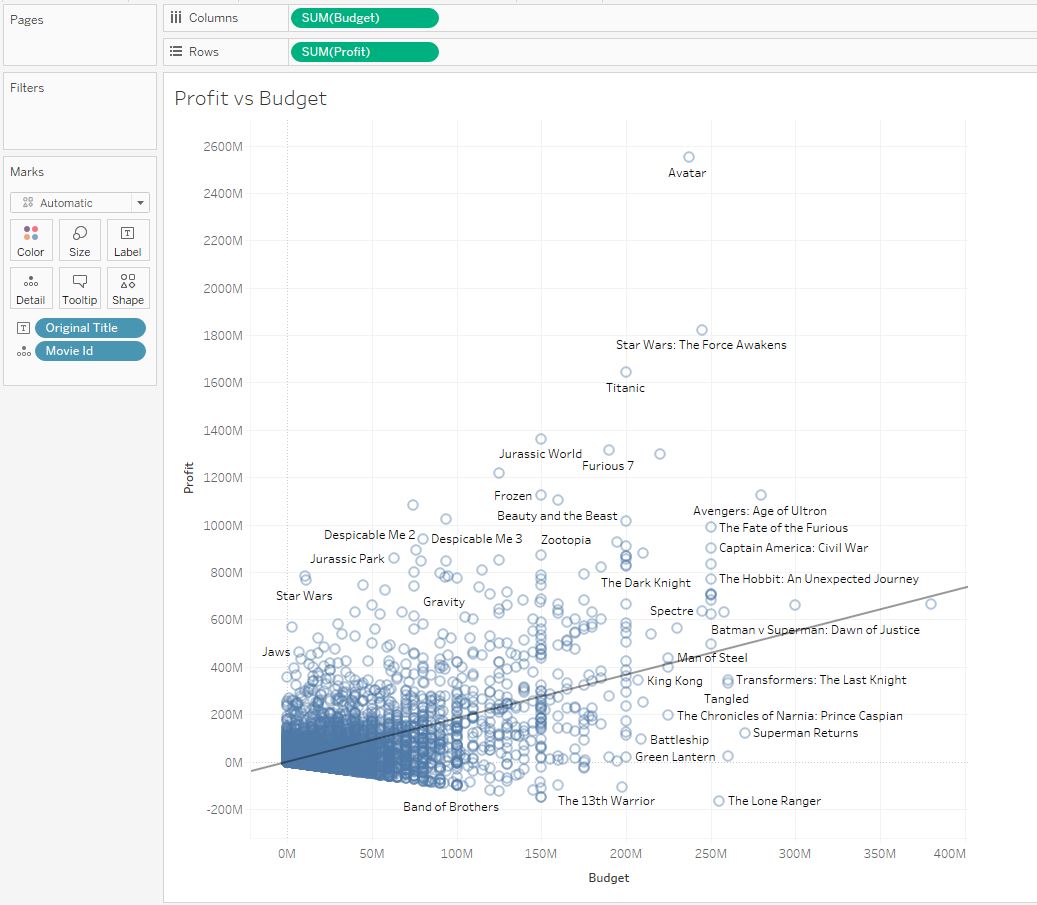
Добавив линию тренда на диаграмму, увидим сильный положительный тренд, то есть, при увеличении бюджета прибыль увеличивается. Так мы подтверждаем первую нашу гипотезу. Но все не так просто, и в общем тренде мы не видим деталей. Давайте посмотрим тренды фильмов по разным языкам, добавив в грануляцию поле Original Language. Мы видим разные тренды:
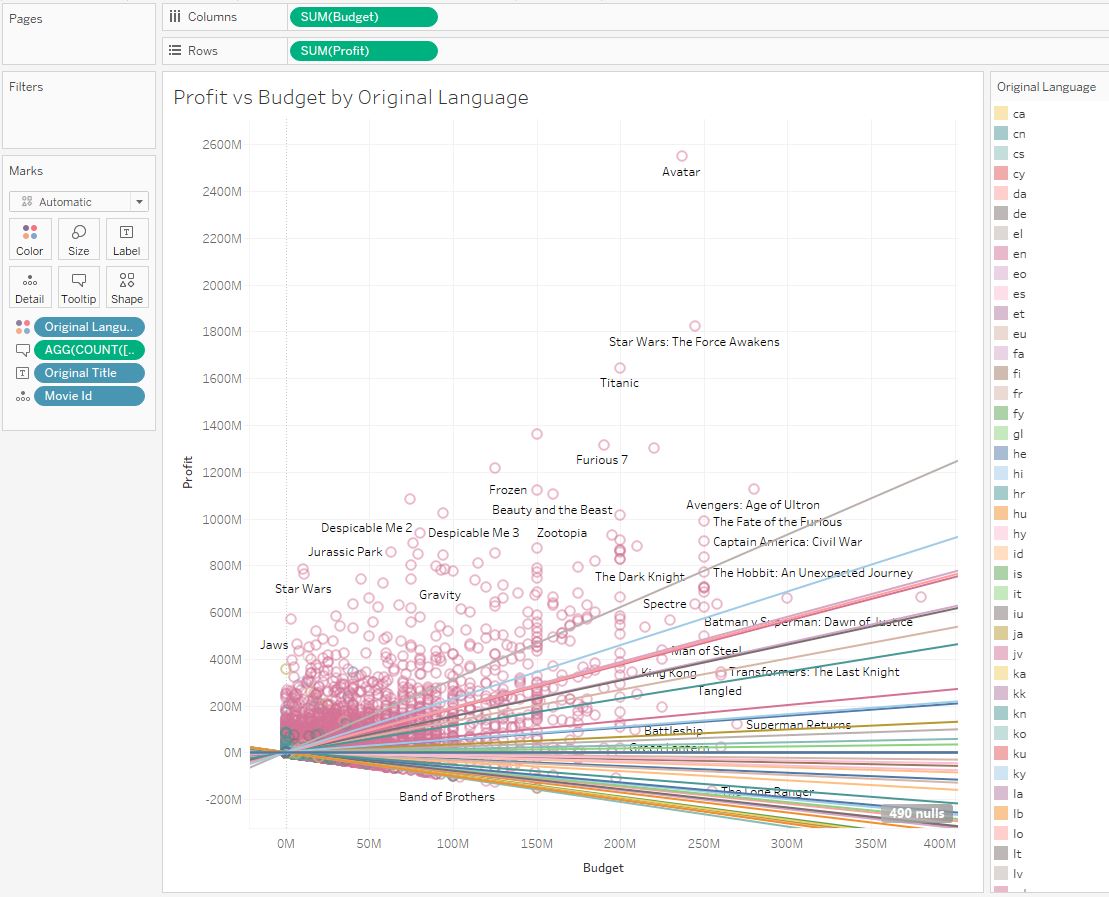
Так мы разбили все фильмы на группы. Давайте посмотрим тренд группы фильмов на английском языке:
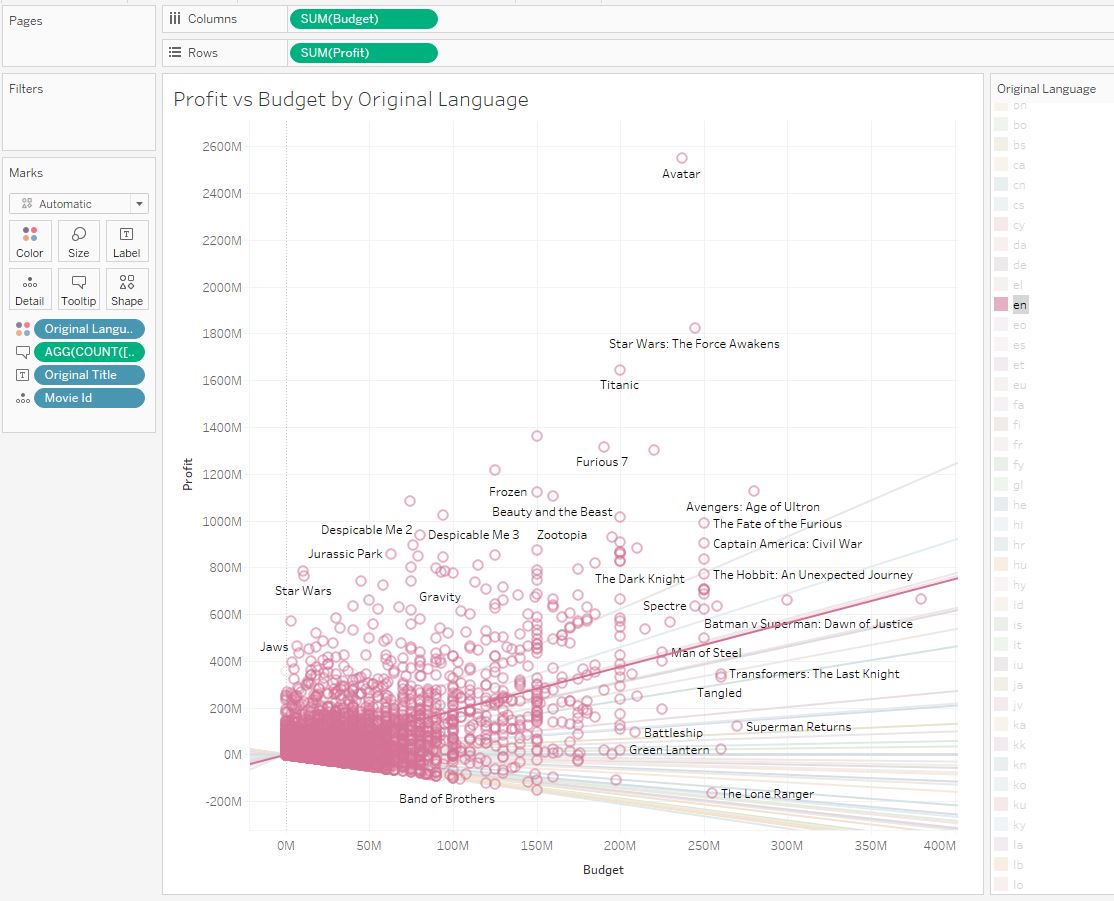
Этот тренд положителен, и в общей картине англоязычных фильмов прибыль увеличивается с ростом бюджета, то есть, большинство фильмов уходят в плюс. Теперь давайте посмотрим тренд фильмов на русском языке:
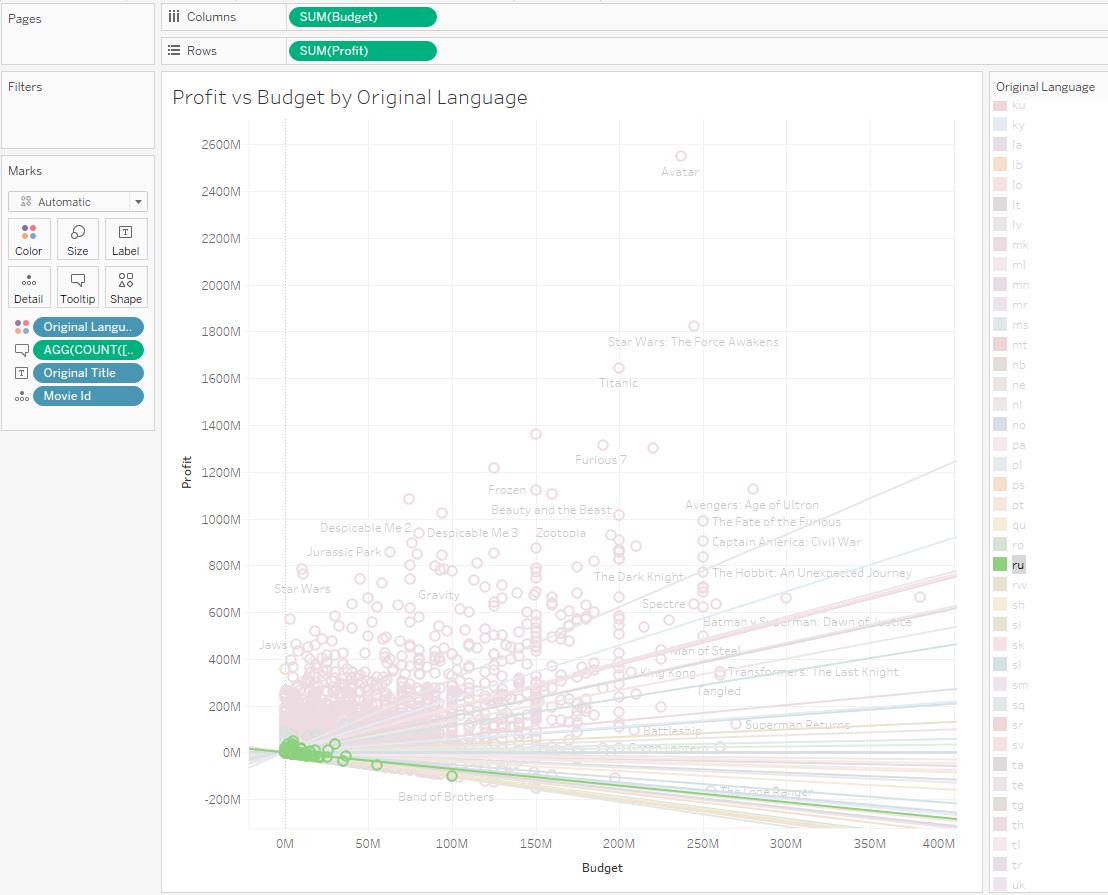
Здесь тренд нисходящий, фильмы становятся убыточными при росте бюджета. На этом примере мы убедились что общий тренд не всегда соответствует групповым трендам.
Важно: в исходных данных есть полная информация далеко не по всем фильмам, поэтому я убрал из данных фильмы с пустыми полями в бюджете, жанре и т.п. В итоге осталось 5230 фильмов.
2. Усложнение групп
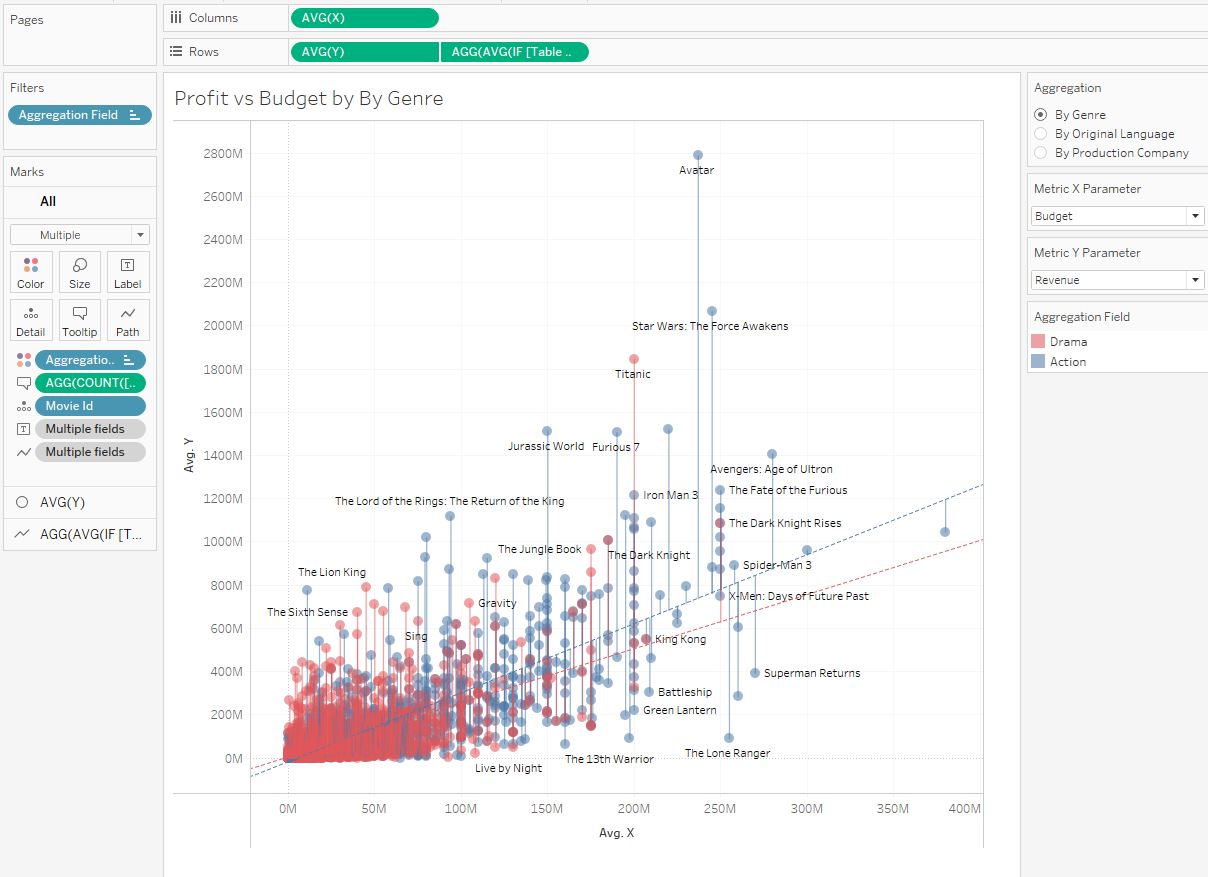
В примере выше один фильм входил только в одну группу (оригинальный язык). В этом разделе рассмотрим пример, когда фильм входит в несколько групп. Предположим что мы хотим посмотреть тренды по жанрам фильмов. Один фильм может входить в несколько жанров сразу. Например, фильм «The Hobbit: An Unexpected Journey» (Хоббит: Нежданное путешествие). «Это фэнтези, приключения и экшн одновременно. В данных в поле жанра Genres это выглядит так:
[{‘id’: 12, ‘name’: ‘Adventure’}, {‘id’: 14, ‘name’: ‘Fantasy’}, {‘id’: 28, ‘name’: ‘Action’}]
Таких сочетаний жанров в данных может быть до шести. Соответственно при разбиении на жанры нужно в группы жанров включить один фильм несколько раз. Но нельзя поле Genres просто добавить в грануляцию — так разбиение на жанры будет работать некорректно. Поэтому модифицируем данные. В датасете нужно в каждой строке получить один фильм и жанр, то есть, одна строка фильма с шестью значениями жанров превратится в 6 строк. Это можно сделать в Tableau Prep, используя Pivot. Разобьем поле Genre на столбцы по сочетанию символов }, {.
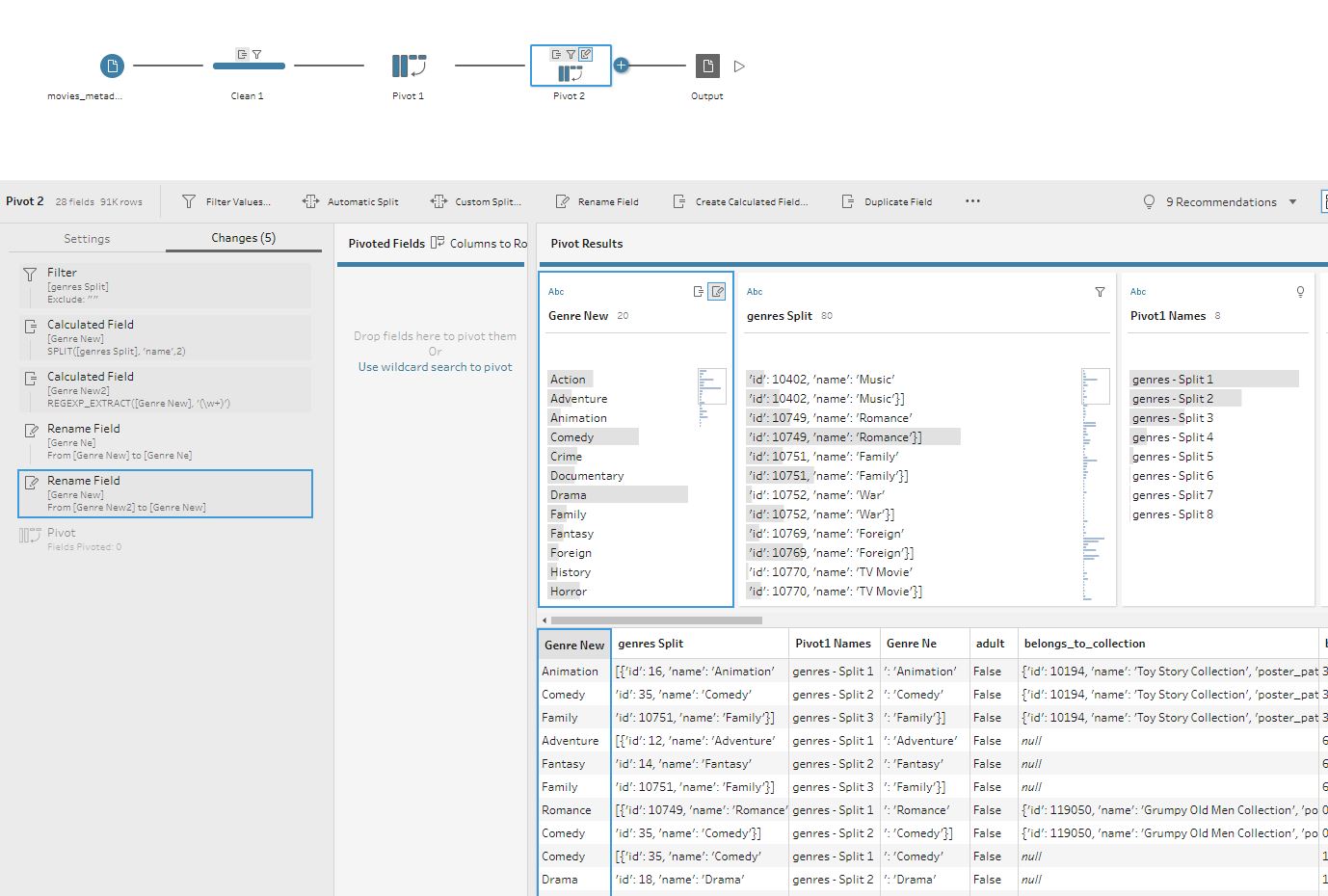
WHEN ‘By Genre’ THEN [Genre New]
WHEN ‘By Original Language’ THEN [Original Language]
WHEN ‘By Production Company’ THEN [Prod]
END
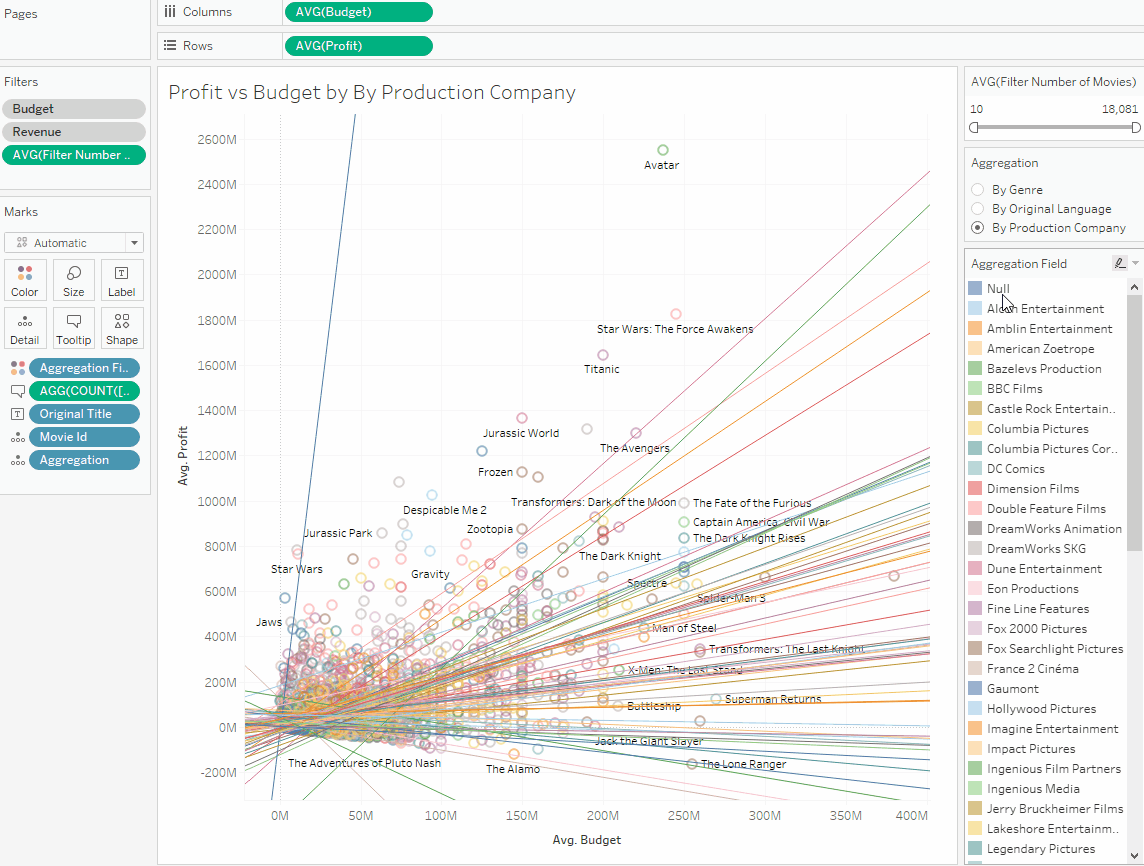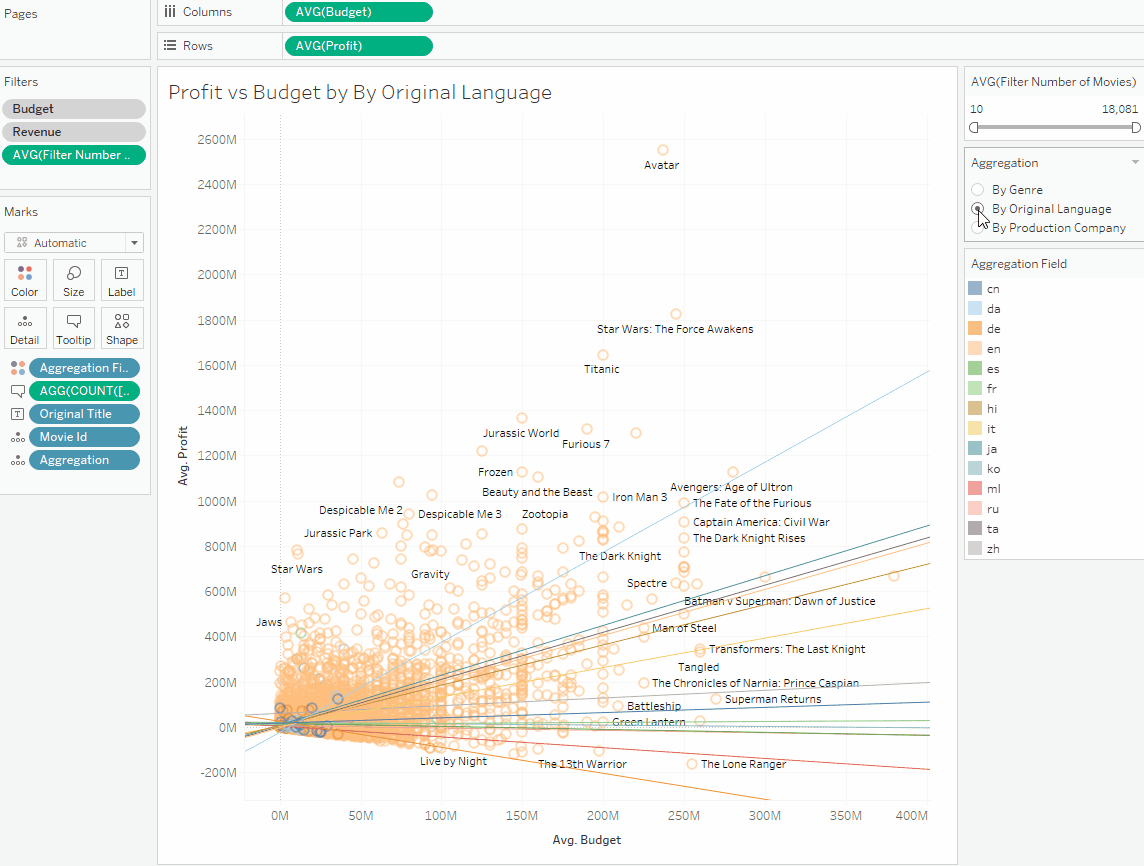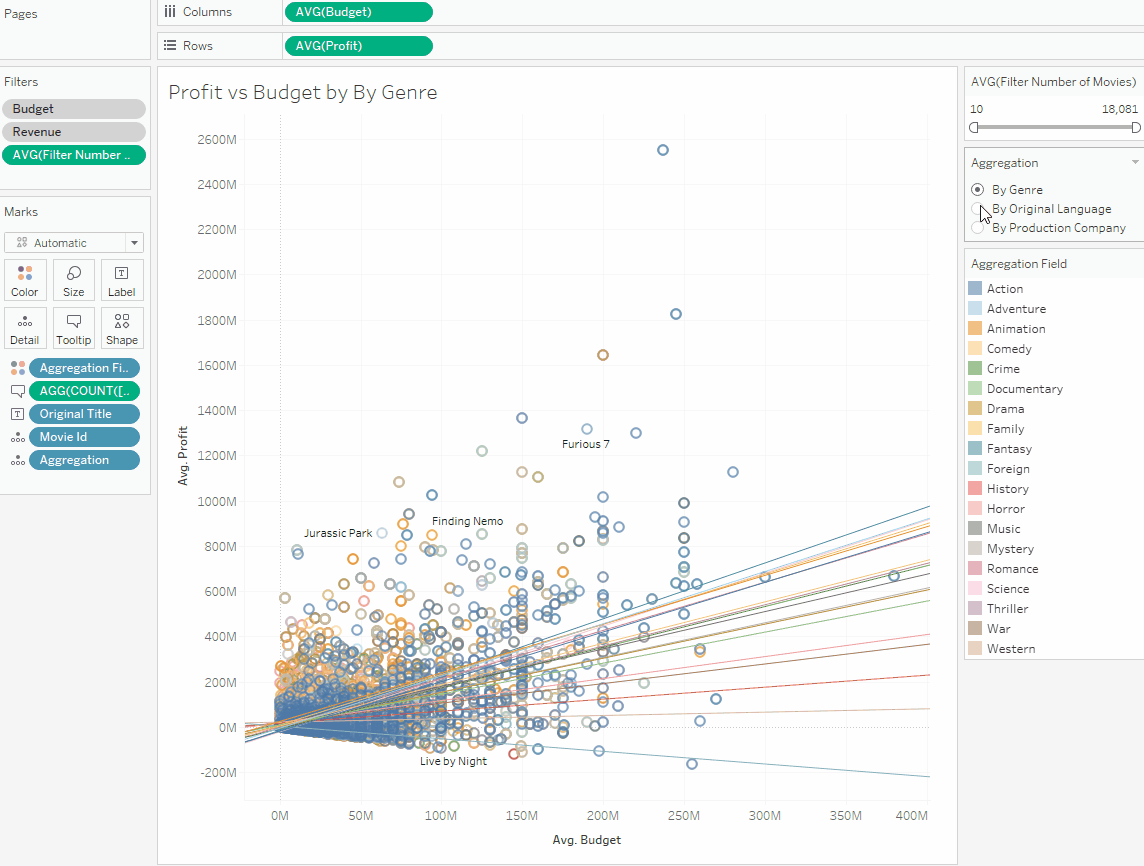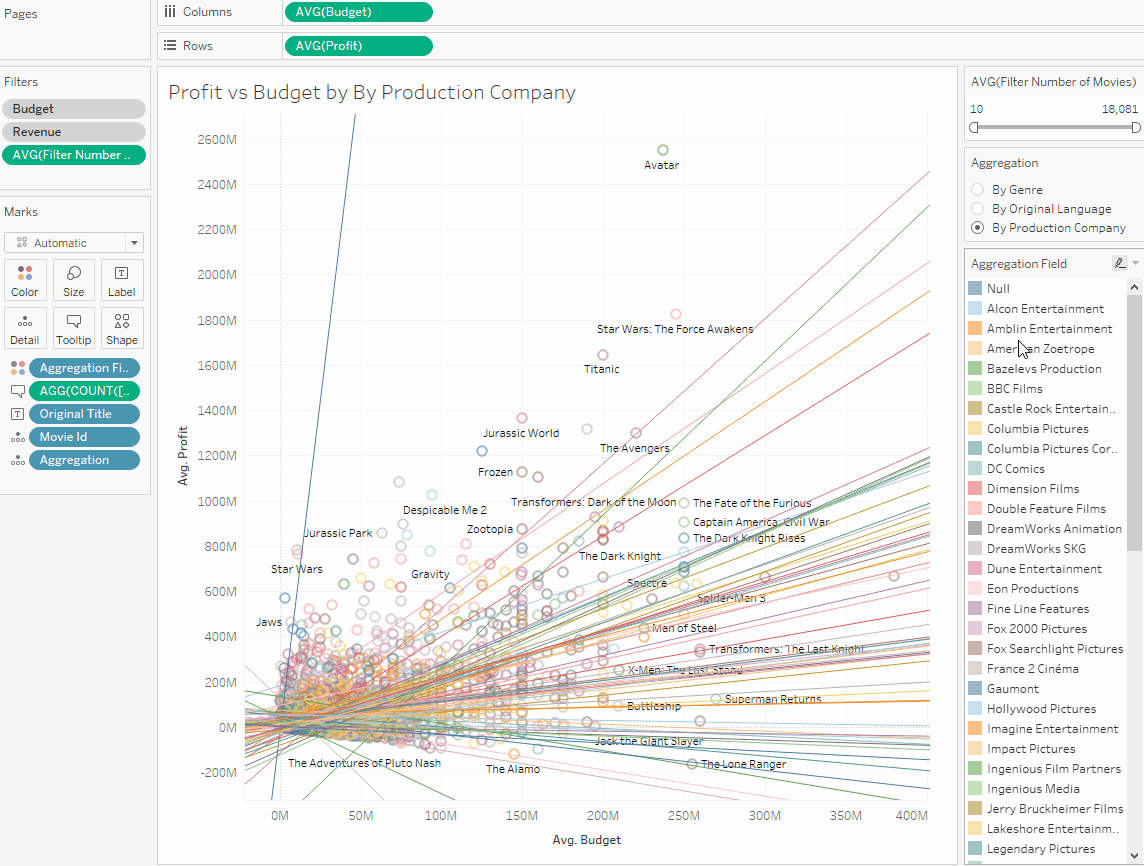
3. Сравнение разных метрик
Чтобы иметь возможность визуализировать тренды между любыми двумя метриками, сделаем возможность переключения метрик как на оси X Так и на оси Y. Для этого создадим текстовый параметров со списком нужных нам метрик и вычисления X и Y:
X
CASE [Metric X Parameter]
WHEN ‘Budget’ THEN [Budget]
WHEN ‘Revenue’ THEN [Revenue]
WHEN ‘Profit’ THEN [Profit]
WHEN ‘MovieLens Rating’ THEN [Rating]
WHEN ‘Vote Count’ THEN [Vote Count]
WHEN ‘Runtime’ THEN [Runtime]
END
Y
CASE [Metric Y Parameter]
WHEN ‘Budget’ THEN [Budget]
WHEN ‘Revenue’ THEN [Revenue]
WHEN ‘Profit’ THEN [Profit]
WHEN ‘MovieLens Rating’ THEN [Rating]
WHEN ‘Vote Count’ THEN [Vote Count]
WHEN ‘Runtime’ THEN [Runtime]
END
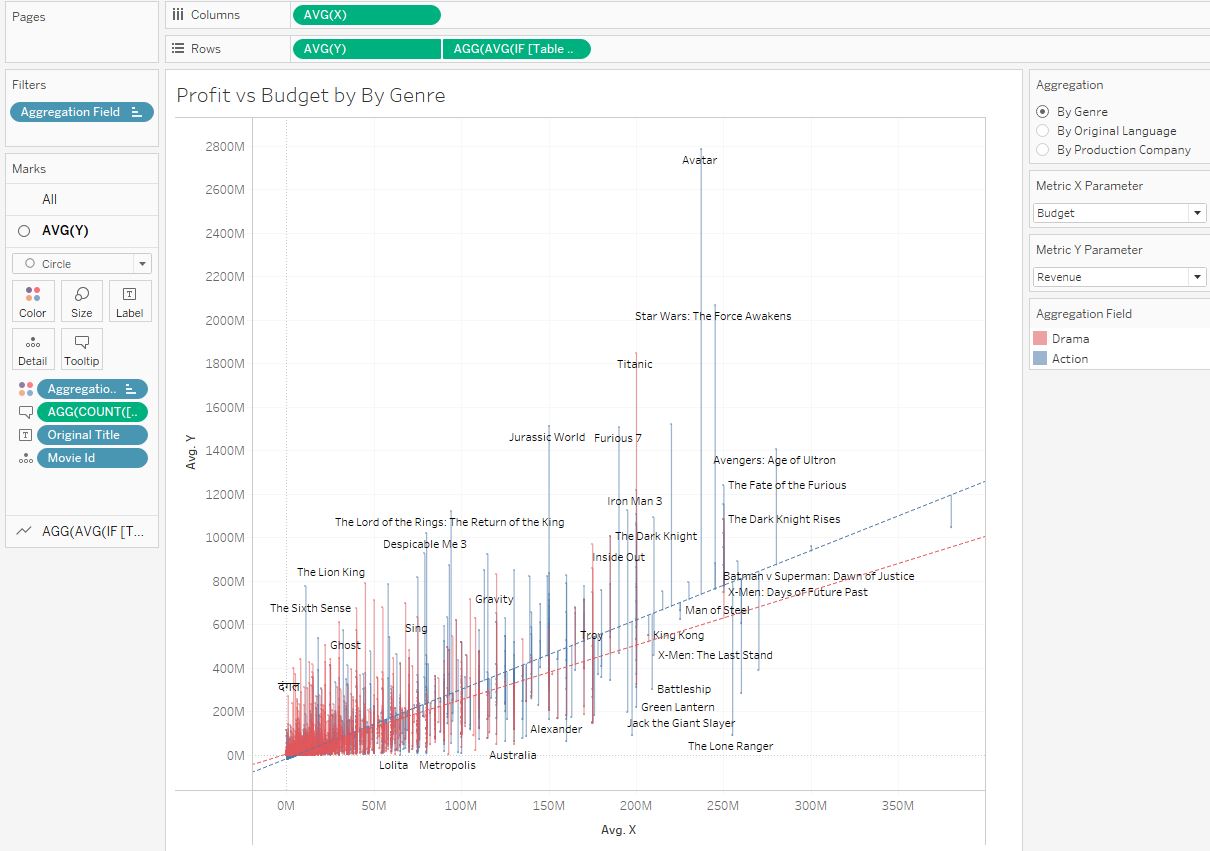
Теперь можно выбирать пару любых метрик и смотреть линейные тренды:
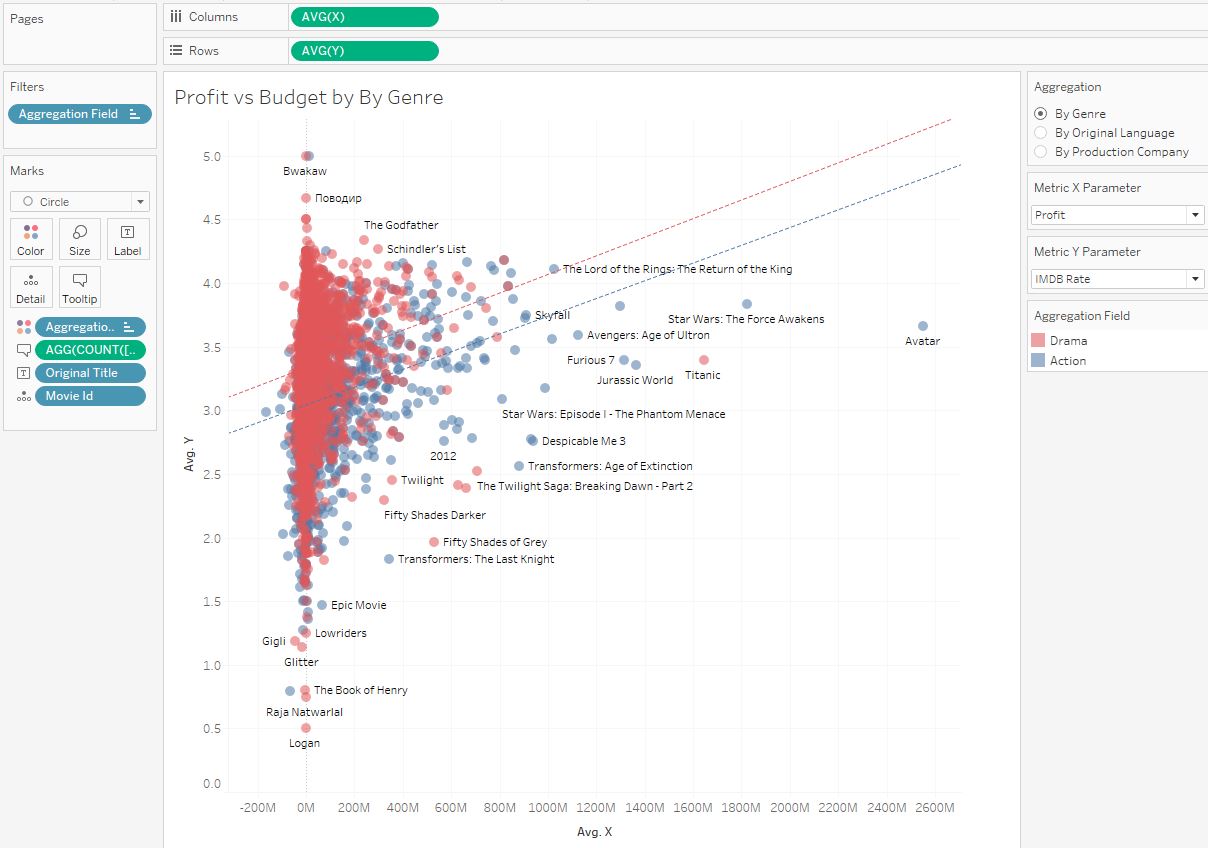
4. Расчет отклонений от тренда
В стaтье «Линейная регрессия в Tableau, часть 1. Временные ряды» я показывал как находить уравнение прямой для линейной регрессии и рассчитывать отклонения точек от линий тренда. Здесь будем применять такой же подход — сначала найдем уравнение прямой тренда.
В измененном датасете каждому жанру одного фильма соответствует одна строка, то есть, фильм может находиться например в шести строках, и чтобы корректно передать результаты метрик Profit, Revenue и т.п. в Tableau, нужно рассчитать среднее значение в этих 6и строках. Сделаем это при помощи FIXED:
X fixed
{ FIXED [Movie Id]: AVG([X])}
Y fixed
{ FIXED [Movie Id]: AVG([Y])}
5. Визуализация отклонений от тренда
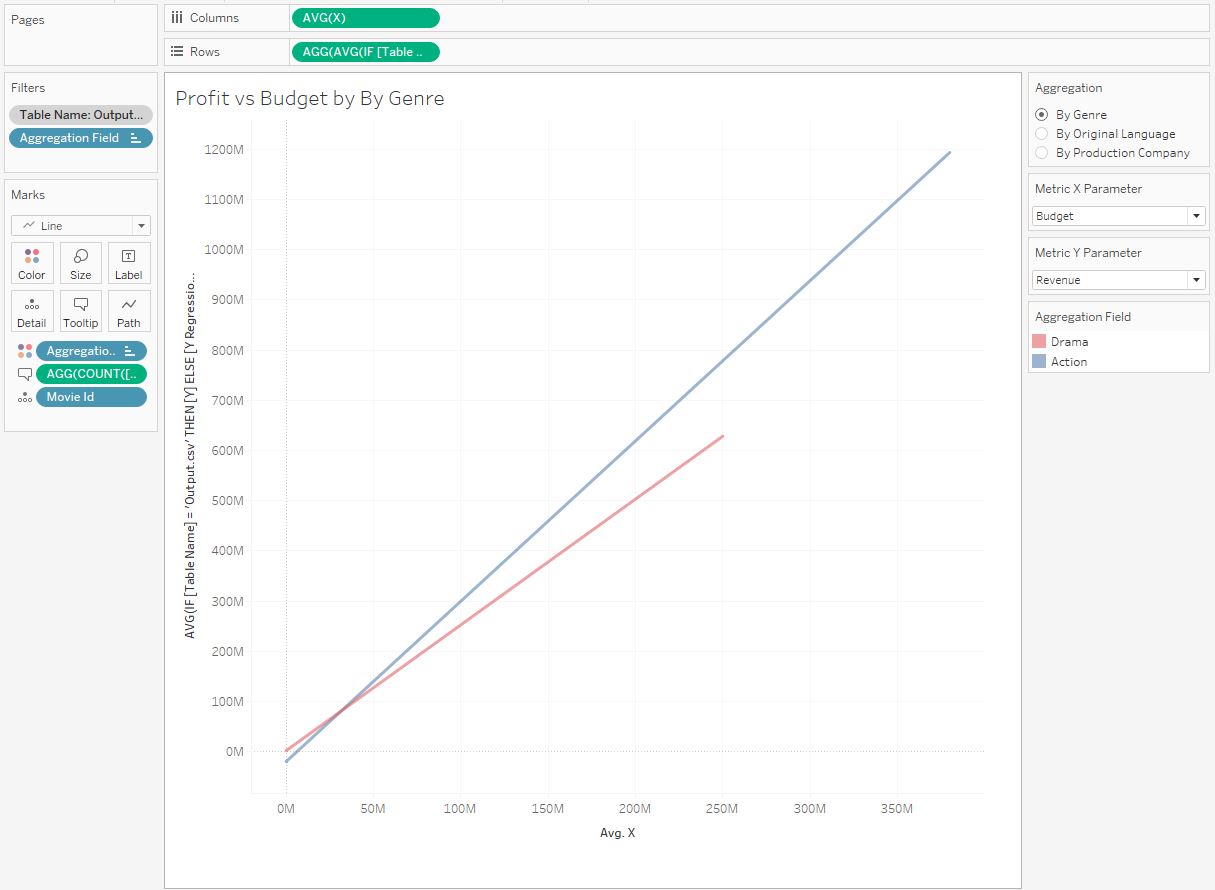
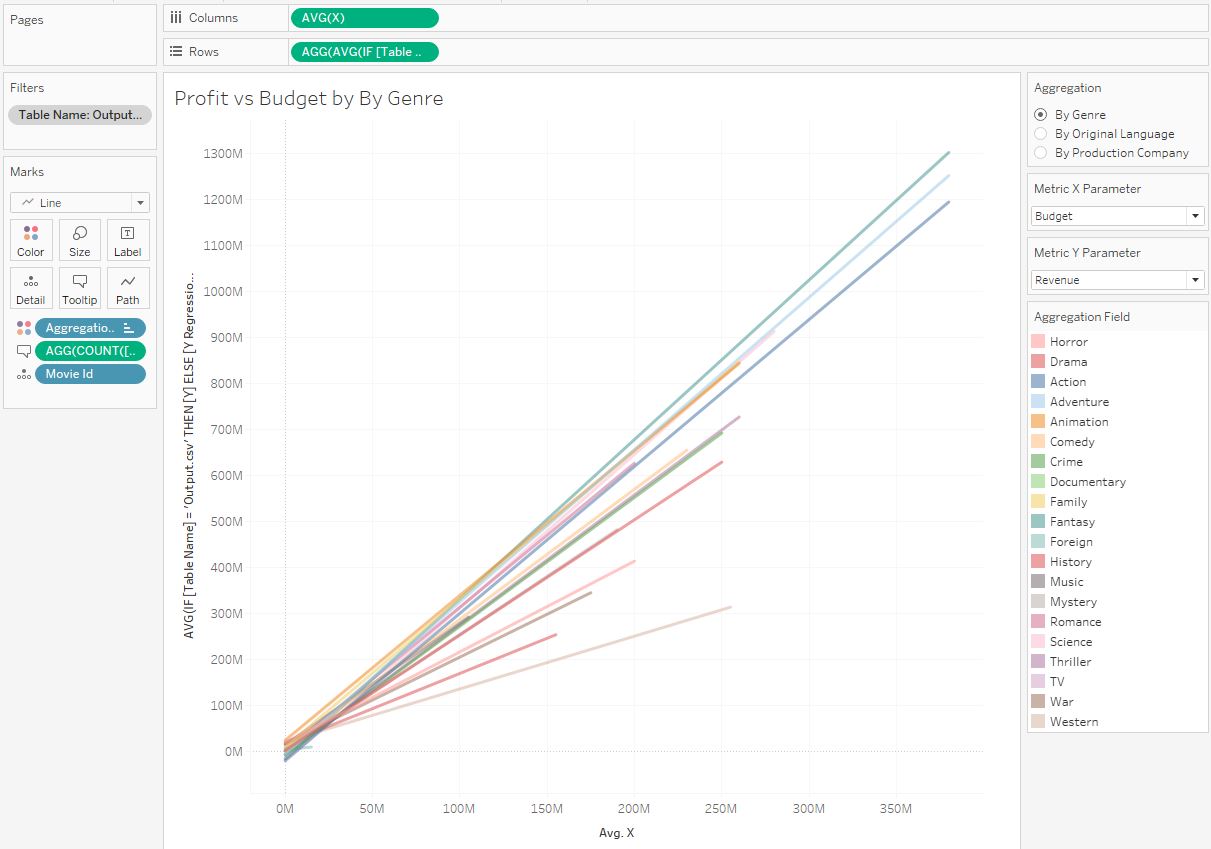
6. Оценка корреляции
В стaтье «Линейная регрессия в Tableau, часть 1. Временные ряды» я рассказал как рассчитывать параметры корреляции, поэтому в этой статье на вычислениях всех параметров останавливаться не будем и возьмем только коэффициент корреляции Пирсона, а также построим шкалу Чеддока.
Коэффициент корреляции Пирсона рассчитаем по формуле Pearson Coef:
{ FIXED [Aggregation Field]: CORR([X fixed],[Y fixed])}
Теперь добавим вычисление в Marks чтобы коэффициент корреляции показывался на диаграмме для каждой точки, но для всех точек одной группы он естественно одинаковый:
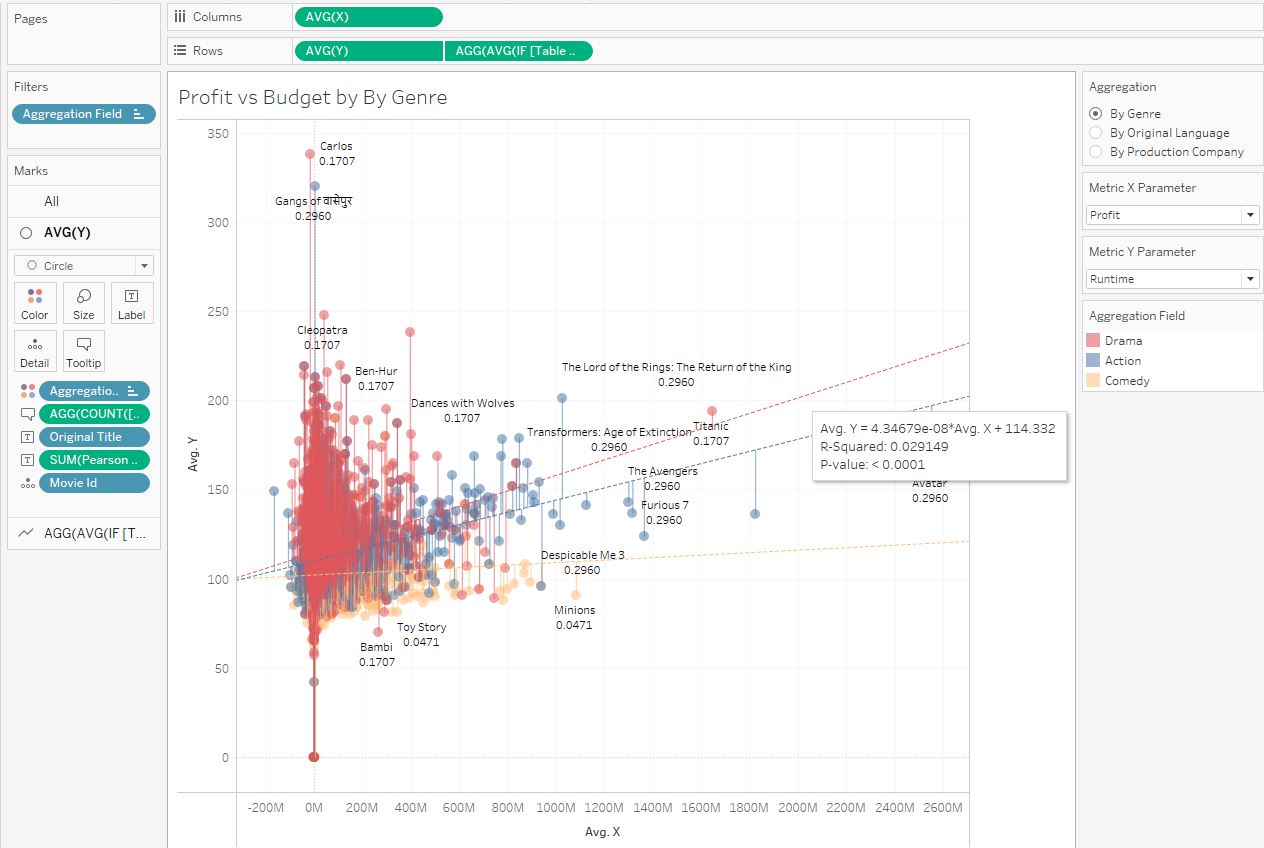
Величина R-Squared на нативной линии тренда — это коэффициент детерминации, и, взяв из него корень, получим коэффициент Пирсона. Так можно проверить свои расчеты.
Про коэффициент корреляции Пирсона я рассказывал в первой части статей о линейной регрессии. Этот коэффициент принимает значения от -1 до 1 и характеризует связь между переменными. Чем ближе значение коэффициента к +1 или -1 тем сильнее связь. Знак же характеризует тип корреляции (прямую или обратную).
На скриншоте выше показана диаграмма разброса длительности фильмов от бюджета фильмов. У комедий коэффициент Пирсона равен 0.0471, от свидетельствует от отсутствии связи между бюджетом и длительностью фильма — комедии. У категории Action коэффициент 0.296, это характеризует заметную связь между бюджетом и длительностью фильма, то есть, чем больше бюджет тем дольше длится фильм.
Поскольку числами коэффициентов оперировать не просто, введем качественную шкалу, отображающую связь между метриками. Это шкала Чеддока. Про создание такой шкалы я писал в статье «Линейная регрессия в Tableau, часть 1. Временные ряды«. Здесь сделаем то же самое, шкалу расположим горизонтально, чтобы она занимала больше места:

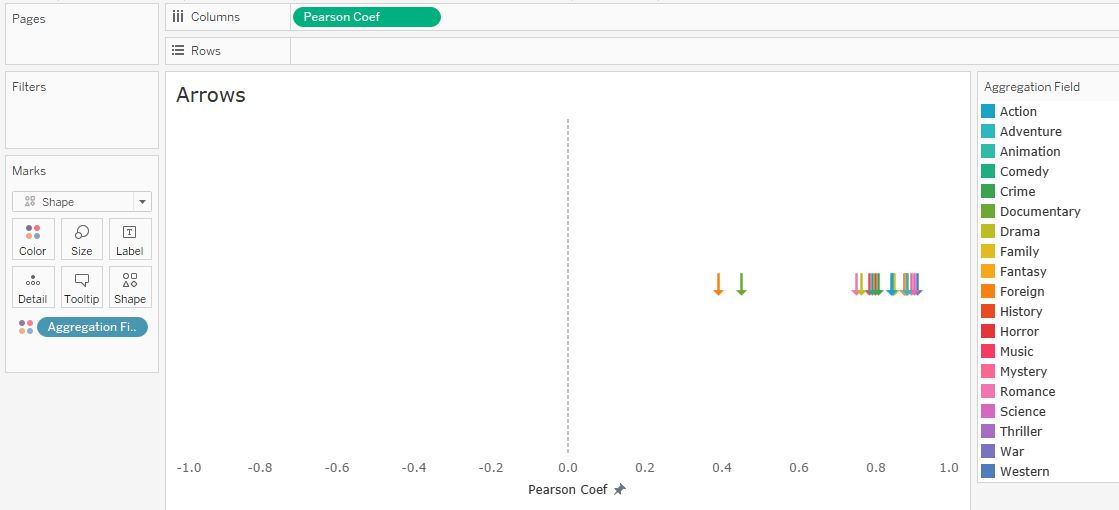
Отдельным листом сделаем индикаторы в виде стрелок — они будут показывать значение коэффициента Пирсона на шкале. Ось X фиксируем от -1 до 1:
7. Финальная визуализация
Для того чтобы создать инструмент поиска инсайтов, добавим фильтры и параметры на визуализацию, а также добавим actions на дашборд для возможности фильтрации с легенды и возможности подсветки (highlight) групп. Чтобы клики по легенде фильтровали данные, сделаем легенду отдельным листом и вставим на визуализацию. Фильтры, параметры и легенду добавим в один контейнер и предусмотрим возможность сворачивания этого контенера по кнопке «Hide Filters». Возможность скрытия Tiled контейнеров новая, и появилась в версии Tableau 2021.2. При скрытии панели фильтров график расширяется на всю ширину дашборда — это очень удобно для детального изучения данных.
Немного поиграем с цветами и шрифтом, получим финальный виз:
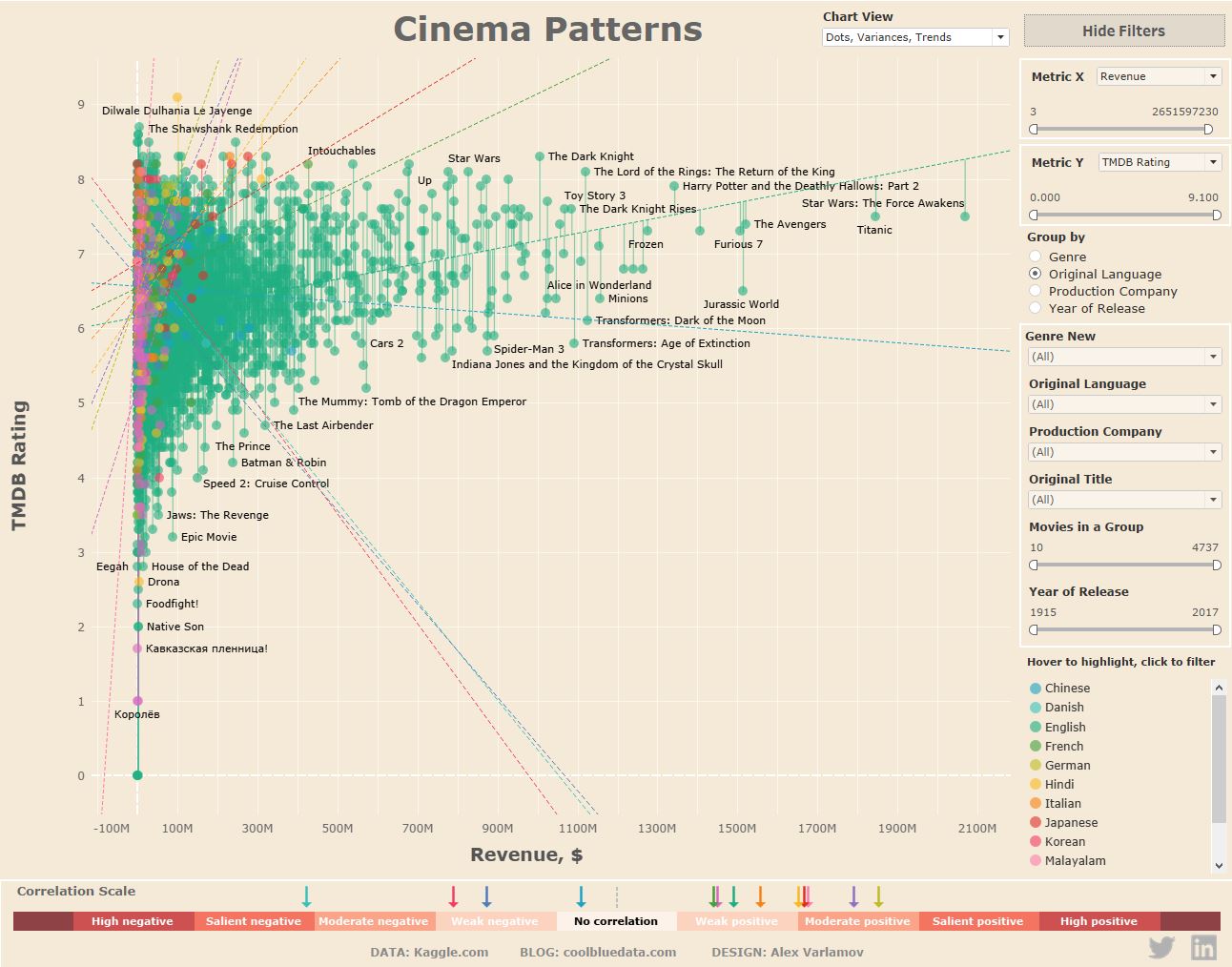
Естественно, большую роль играют фильтры для отбора интересующих групп, но можно смотреть общие картины, например посмотреть корреляцию между TMDB рейтингом и кассовыми сборами фильмов на различных языках.
Заключение
В этой статье я показал как можно визуализировать связь между двумя метриками, а также разбивать данные на группы при помощи параметров и сравнивать поведение трендов разных групп.
В статье был создан инструмент, позволяющий по-разному смотреть на данные и находить взаимосвязи и инсайты в этих данных, подтверждать или опровергать гипотезы.
Надо отметить что поиск взаимосвязей в данных — повседневная работа аналитиков данных, и в задачах бизнеса подобные инструменты воcтребованы. По опыту могу сказать что дашборды с «батареей» фильтров и параметров, позволяющие пользователю по-разному взглянуть на данные работают намного лучше неинтерактивных печатных дашбордов.